Job
需求来源
Job 背景问题
在 K8s 里,最小的调度单元是 Pod,可以直接通过 Pod 来运行任务进程。这样做会产生以下几种问题:
- 如何保证 Pod 内进程正确的结束?
- 如何保证进程运行失败后重试?
- 如何管理多个任务,且任务之间有依赖关系?
- 如何并行地运行任务,并管理任务的队列大小?
Job:管理任务的控制器
Job 提供了以下功能:
首先 K8s 的 Job 是一个管理任务的控制器,可以创建一个或多个 Pod 来指定 Pod 的数量,并可以监控它是否成功地运行或终止; 可以根据 Pod 的状态来给 Job 设置重置的方式及重试的次数; 可以根据依赖关系,保证上一个任务运行完成之后再运行下一个任务; 可以控制任务的并行度,根据并行度来确保 Pod 运行过程中的并行次数和总体完成大小。
用例解读
Job 语法
|
|
- restartPolicy:可以设置 Never、OnFailure、Always 这三种重试策略。在希望 Job 需要重新运行的时候,可以用 Never;希望在失败的时候再运行,再重试可以用 OnFailure;或者不论什么情况下都重新运行时 Always;
- backoffLimit:控制 Job 重试的次数。
并行运行 Job
|
|
有时会有并行运行的需求:希望 Job 运行的时候可以最大化的并行,并行出 n 个 Pod 去快速地执行。同时,也不希望同时并行的 Pod 数过多。
- completions:指定本 Pod 队列执行次数,或者理解为指定可以运行的总次数;
- parallelism:并行执行的个数。
CronJob 语法
|
|
CronJob,也叫做定时运行 Job,可以设定一个事件去执行;
- schedule:设置时间格式,和 Linux 的 crontime 是一样的,直接根据 Linux 的 crontime 书写格式来写就可以了
- startDeadlineSeconds:每次运行 Job 的时候,最长可以等多长时间,有时 Job 可能运行很长时间也不会启动。如果超过较长时间的话,CronJob 就会停止这个 Job;
- concurrencyPolicy:是否允许并行运行,如果设置允许,则不管前面的 Job 是否运行完成,后面的 Job 每分钟都会执行,如果是 false,则等待上个结束再运行下一个;
- JobsHistoryLimit:留存历史版本数量。
架构设计
Job Architecture
- Job Controller 创建相对应的 pod;
- Job Controller 跟踪 Job 状态,根据配置及时重试 Pod 或者继续创建;
- Job Controller 会自动添加 label 来跟踪对应的 pod,并根据配置并行或串行创建 Pod。
Job 控制器
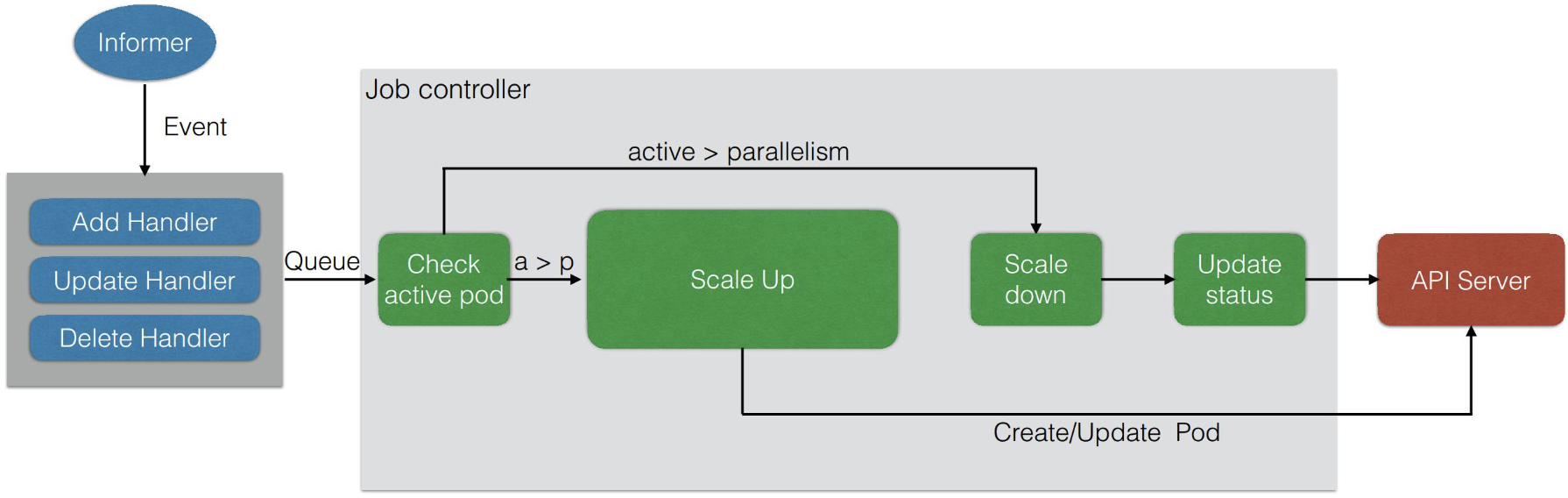
Job Controller
所有 Job 都是一个 controller,它会 watch 这个 API Server,每次提交一个 Job 的 yaml 都会经过 api-server 传到 etcd 里面去,然后 Job Controller 会注册几个 Handler,每当有添加、更新、删除等操作的时候,会通过一个内存级的消息队列,发到 controller 里面。
通过 Job Controller 检查当前是否有运行的 Pod,如果没有的话,通过 Scale up 把这个 Pod 创建出来;如果有的话,或者大于这个数,对它进行 Scale down,如果这时 Pod 发生变化,需要及时更新状态。
同时要去检查它是否是并行的 job,或者是串行的 job,根据设置的配置并行度、串行度,及时地把 pod 的数量给创建出来。最后,它会把 job 的整个的状态更新到 API Server 里面去,这样就能看到呈现出来的最终效果了。
Комментарии