背景
DataSource V2 是 Spark 2.X 新推出的 API,主要目的是集成外部数据存储,实现读写操作。但这里缺少了关键的一环:对表的元数据进行操作,比如创建、修改、删除表等。
Spark SQL 和 DataFrame 操作都支持 CTAS(Create Table As Select)用来创建一个表并向该表写入数据。由于缺少创建表的 API,CTAS 失败后,表可能被保存也可能被删除。在某些 SaveMode 下,我们无法区分 CTAS 和普通写操作,那么很有可能在 Append 模式下写表的时候会因为表被删除而失败。最后一点,Spark 无法设置由 CTAS 创建的表,比如分区。
此外,用户希望 CTAS 的 high-level 操作在数据源上面进行操作时能保持行为一致。举个例子,Spark 使用 CTAS 写入失败的时候,当元数据管理不可用,CTAS 可能会无法删表。这要求 Catalog API 能对那些数据源进行创建、修改以及删除等操作。
另外,使用 DataFrame 编写 Spark 程序时可以使用 SQL 引擎,但没有类似创建、修改、删除这种 Catalog API 提供。
Catalog Plugin 的首要目标其实是提供一组 catalog API 用来创建、修改、加载和删除表。
更详细情况,请参考 Spark Catalog Plugin 设计文档: https://docs.google.com/document/d/1zLFiA1VuaWeVxeTDXNg8bL6GP3BVoOZBkewFtEnjEoo/edit
Catalog Plugin Interface
自定义 Catalog 必须实现 CatalogPlugin 接口,通过 load(String, SQLConf)#Catalogs 进行加载,加载时会调用具体 Catalogs 的无参构造函数方法进行初始化,初始化之后会调用 initialize#CatalogPlugin(Line #60)进行初始化。
使用 Catalog Plugin 需要添加如下配置,其中第二个配置是通过 catalogOptions#Catalogs(Line #87) 传递给 initialize#CatalogPlugin 的参数
- spark.sql.catalog.<catalog-name>=<YourCatalogClass>
- spark.sql.catalog.catalog-name.(key)=(value)
Catalog Plugin Interface 的实现和继承关系如下图所示,可以看到 TableCatalog Interface 继承了 CatalogPlugin,然后 V2SessionCatalog 和 JDBCTableCatalog 是两个具体的 class,实现了 TableCatalog。
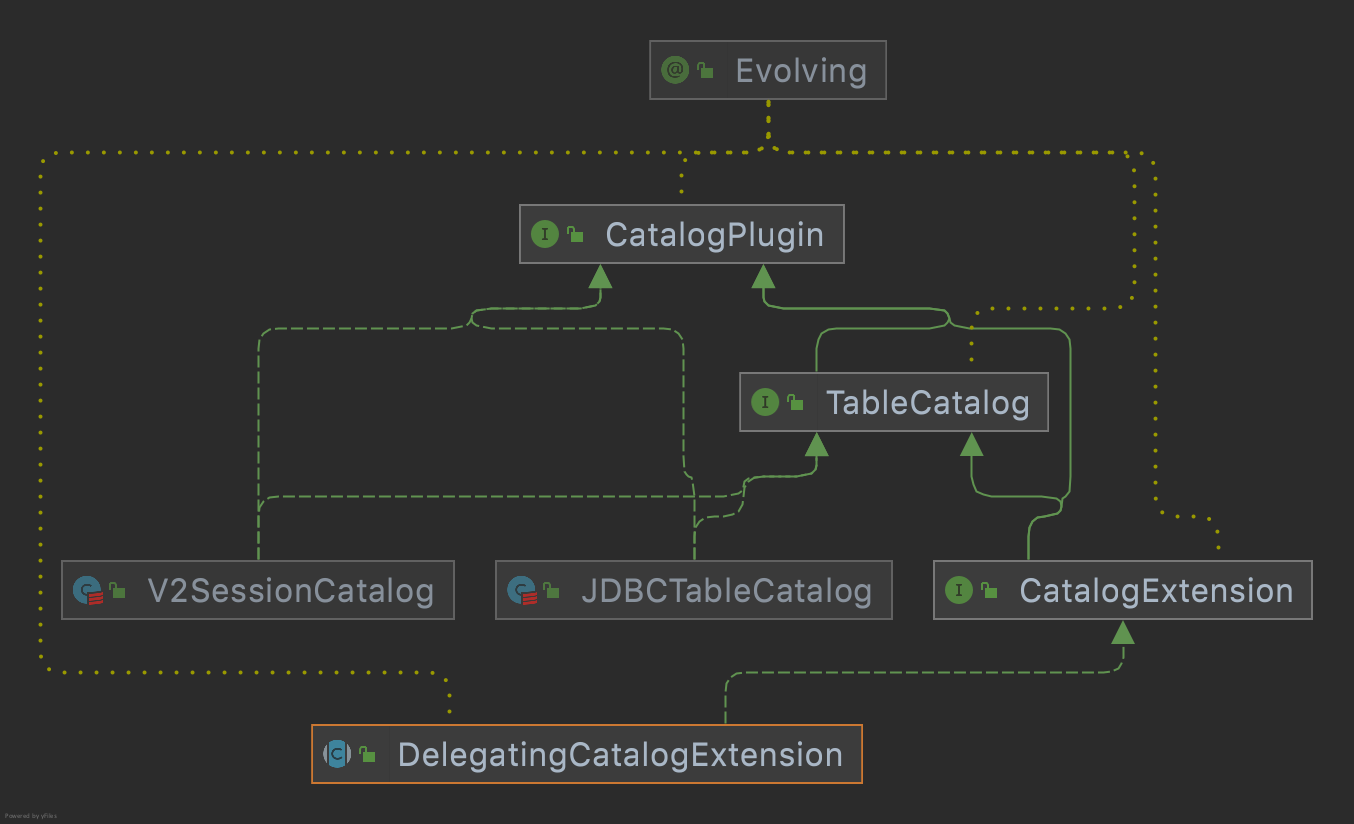
Implementations of CatalogPlugin
TableCatalog
TableCatalog 定义了 Catalog 和表交互的方法,定义都非常简单。
CatalogManager
前期配置的时候出现配置 spark.sql.catalog.<catalog-name>=<YourCatalogClass>,我们可以合理怀疑所有的 Catalog 都是通过一个 Map 映射关系来管理的,这个管理的 Class 就是 CatalogManager。
从 CatalogManager 的注释中我们可以看出这就是一个 CatalogPlugin 的管理者,并且是线程安全的。
- catalogs:一个
map: mutable.HashMap[String, CatalogPlugin],保存 catalog 名字和 Class 的隐射关系 - catalog(String):用来查找特定名字的 Catalog,返回 CatalogPlugin 接口。
CatalogExtension & DelegatingCatalogExtension
CatalogExtension 继承了 TableCatalog,通过 setDelegateCatalog() 方法代理 V2SessionCatalog。
DelegatingCatalogExtension 实现了上面抽象类的所有默认方法,其 subClass 可以通过 super.func(ident) 调用默认实现。如果要对现有的 catalog 进行功能扩展,可以直接继承实现对应的逻辑。具体可参考 Delta 的 DeltaCatalog
Catalog Plugin 全链路流程
- SparkSession 在创建的选项中可以使用 enableHiveSupport() 启动 Hive 作为 catalog 实现,在这个方法内会设置参数
spark.sql.catalogImplementation = hive; - 根据
spark.sql.catalogImplementation创建HiveSessionStateBuilder对象,HiveSessionStateBuilder会创建 catalog 对象,BaseSessionStateBuilder再根据 catalog 创建 v2SessionCatalog 对象; - 根据 catalog 和 v2SessionCatalog 创建
CatalogManager实例。CatalogManager通过 catalogs 来管理多个 catalog,CatalogMannager 的 defaultSessionCatalog 就是上面的 v2SessionCatalog; catalog(name: String)#CatalogManager通过 catalog 的 name 返回 catalog 实例,如果没有该实例,通过Catalogs.load(name: String, ...)方法进行实例化;Catalogs.load(name: String, ...)方法加载 conf 中配置的spark.sql.catalog.<catalog-name>类,并实例化/初始化 CatalogPlugin 对象;- 有一个特殊的 catalog——spark_catalog。如果
spark.sql.catalog.spark_catalog参数为空时,返回 CatalogManager 中的 defaultSessionCatalog; - 如果
spark.sql.catalog.spark_catalog参数已经配置,对上面的 Catalogs.load() 出来的实例进行判断,如果发现上面加载的是 CatalogExtension 子类,自动调用其setDelegateCatalog方法,将 defaultSessionCatalog 设置为其内部代理对象; - 调用元数据相关操作时,实例化 HiveClient,调用 Hive MetaStore 提供的接口,完成元数据的相关操作,Hive MetaStore 具体操作由
ThriftHiveMetastore.Iface实现。
Комментарии