// controller.go
// submitSparkApplication creates a new submission for the given SparkApplication and submits it using spark-submit.
func(c*Controller)submitSparkApplication(app*v1beta2.SparkApplication)*v1beta2.SparkApplication{ifapp.PrometheusMonitoringEnabled(){...configPrometheusMonitoring(app,c.kubeClient)}// Use batch scheduler to perform scheduling task before submitting (before build command arguments).
ifneedScheduling,scheduler:=c.shouldDoBatchScheduling(app);needScheduling{newApp,err:=scheduler.DoBatchSchedulingOnSubmission(app)...//Spark submit will use the updated app to submit tasks(Spec will not be updated into API server)
app=newApp}driverPodName:=getDriverPodName(app)submissionID:=uuid.New().String()submissionCmdArgs,err:=buildSubmissionCommandArgs(app,driverPodName,submissionID)...// Try submitting the application by running spark-submit.
submitted,err:=runSparkSubmit(newSubmission(submissionCmdArgs,app))...app.Status=v1beta2.SparkApplicationStatus{SubmissionID:submissionID,AppState:v1beta2.ApplicationState{State:v1beta2.SubmittedState,},DriverInfo:v1beta2.DriverInfo{PodName:driverPodName,},SubmissionAttempts:app.Status.SubmissionAttempts+1,ExecutionAttempts:app.Status.ExecutionAttempts+1,LastSubmissionAttemptTime:metav1.Now(),}c.recordSparkApplicationEvent(app)service,err:=createSparkUIService(app,c.kubeClient)...ingress,err:=createSparkUIIngress(app,*service,c.ingressURLFormat,c.kubeClient)returnapp}
// submission.go
funcrunSparkSubmit(submission*submission)(bool,error){sparkHome,present:=os.LookupEnv(sparkHomeEnvVar)if!present{glog.Error("SPARK_HOME is not specified")}varcommand=filepath.Join(sparkHome,"/bin/spark-submit")cmd:=execCommand(command,submission.args...)glog.V(2).Infof("spark-submit arguments: %v",cmd.Args)output,err:=cmd.Output()glog.V(3).Infof("spark-submit output: %s",string(output))iferr!=nil{varerrorMsgstringifexitErr,ok:=err.(*exec.ExitError);ok{errorMsg=string(exitErr.Stderr)}// The driver pod of the application already exists.
ifstrings.Contains(errorMsg,podAlreadyExistsErrorCode){glog.Warningf("trying to resubmit an already submitted SparkApplication %s/%s",submission.namespace,submission.name)returnfalse,nil}iferrorMsg!=""{returnfalse,fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %s",submission.namespace,submission.name,errorMsg)}returnfalse,fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %v",submission.namespace,submission.name,err)}returntrue,nil}funcbuildSubmissionCommandArgs(app*v1beta2.SparkApplication,driverPodNamestring,submissionIDstring)([]string,error){...options,err:=addDriverConfOptions(app,submissionID)...options,err=addExecutorConfOptions(app,submissionID)...}funcgetMasterURL()(string,error){kubernetesServiceHost:=os.Getenv(kubernetesServiceHostEnvVar)...kubernetesServicePort:=os.Getenv(kubernetesServicePortEnvVar)...returnfmt.Sprintf("k8s://https://%s:%s",kubernetesServiceHost,kubernetesServicePort),nil}
// controller.go
func(c*Controller)getAndUpdateAppState(app*v1beta2.SparkApplication)error{iferr:=c.getAndUpdateDriverState(app);err!=nil{returnerr}iferr:=c.getAndUpdateExecutorState(app);err!=nil{returnerr}returnnil}// getAndUpdateDriverState finds the driver pod of the application
// and updates the driver state based on the current phase of the pod.
func(c*Controller)getAndUpdateDriverState(app*v1beta2.SparkApplication)error{// Either the driver pod doesn't exist yet or its name has not been updated.
...driverPod,err:=c.getDriverPod(app)...ifdriverPod==nil{app.Status.AppState.ErrorMessage="Driver Pod not found"app.Status.AppState.State=v1beta2.FailingStateapp.Status.TerminationTime=metav1.Now()returnnil}app.Status.SparkApplicationID=getSparkApplicationID(driverPod)...newState:=driverStateToApplicationState(driverPod.Status)// Only record a driver event if the application state (derived from the driver pod phase) has changed.
ifnewState!=app.Status.AppState.State{c.recordDriverEvent(app,driverPod.Status.Phase,driverPod.Name)}app.Status.AppState.State=newStatereturnnil}// getAndUpdateExecutorState lists the executor pods of the application
// and updates the executor state based on the current phase of the pods.
func(c*Controller)getAndUpdateExecutorState(app*v1beta2.SparkApplication)error{pods,err:=c.getExecutorPods(app)...executorStateMap:=make(map[string]v1beta2.ExecutorState)varexecutorApplicationIDstringfor_,pod:=rangepods{ifutil.IsExecutorPod(pod){newState:=podPhaseToExecutorState(pod.Status.Phase)oldState,exists:=app.Status.ExecutorState[pod.Name]// Only record an executor event if the executor state is new or it has changed.
if!exists||newState!=oldState{c.recordExecutorEvent(app,newState,pod.Name)}executorStateMap[pod.Name]=newStateifexecutorApplicationID==""{executorApplicationID=getSparkApplicationID(pod)}}}// ApplicationID label can be different on driver/executors. Prefer executor ApplicationID if set.
// Refer https://issues.apache.org/jira/projects/SPARK/issues/SPARK-25922 for details.
...ifapp.Status.ExecutorState==nil{app.Status.ExecutorState=make(map[string]v1beta2.ExecutorState)}forname,execStatus:=rangeexecutorStateMap{app.Status.ExecutorState[name]=execStatus}// Handle missing/deleted executors.
forname,oldStatus:=rangeapp.Status.ExecutorState{_,exists:=executorStateMap[name]if!isExecutorTerminated(oldStatus)&&!exists{// If ApplicationState is SUCCEEDING, in other words, the driver pod has been completed
// successfully. The executor pods terminate and are cleaned up, so we could not found
// the executor pod, under this circumstances, we assume the executor pod are completed.
ifapp.Status.AppState.State==v1beta2.SucceedingState{app.Status.ExecutorState[name]=v1beta2.ExecutorCompletedState}else{glog.Infof("Executor pod %s not found, assuming it was deleted.",name)app.Status.ExecutorState[name]=v1beta2.ExecutorFailedState}}}returnnil}
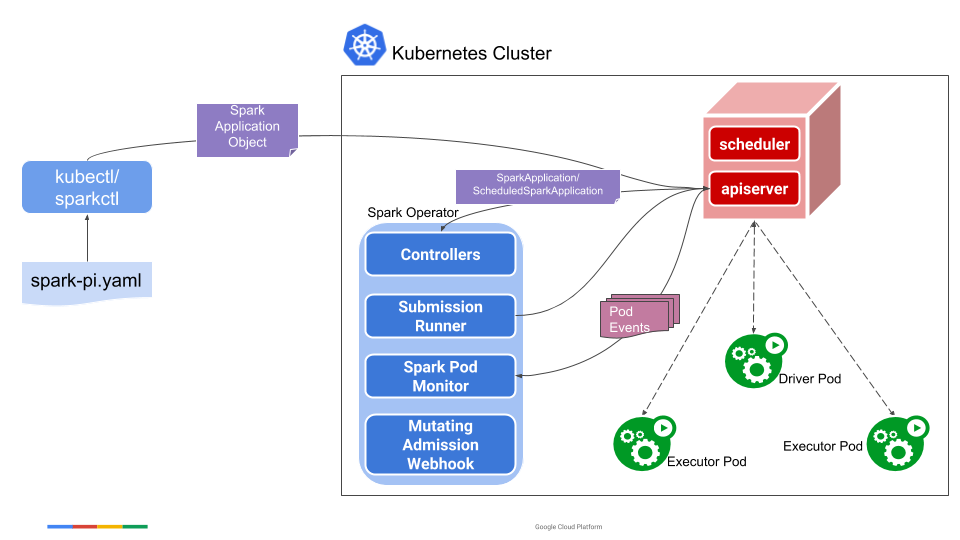
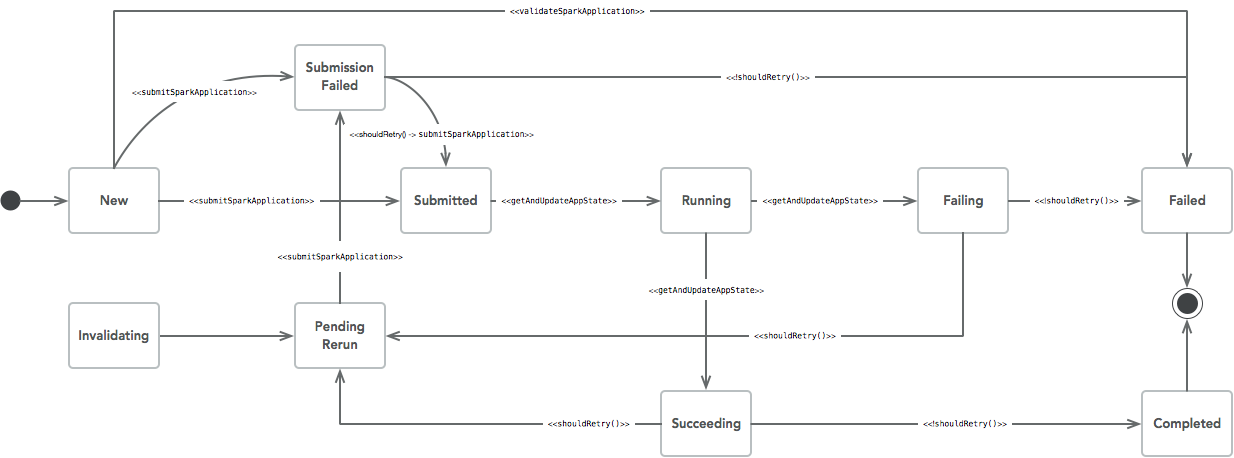
从这段代码可以看到,Spark Application 提交后,Controller 会通过监听 Driver Pod 和Executor Pod 状态来计算 Spark Application 的状态,推动状态机的流转。
Комментарии